# HTTP 协议总结
HTTP 协议是超文本传输协议,是用于从万维网服务器传输到本地浏览器的一种传输协议,网站的图片,js,css 都是基于 http 协议进行传输的。
- HTTP 协议的历史演变
- HTTP 请求与相应
- HTTP 缓存策略
# HTTP 协议的历史演变
# HTTP/0.9
HTTP 最早版本是 1991 年发布的 0.9 版。该版本极其简单,只有一个命令 GET。
GET /index.html
上面命令表示,TCP 连接建立后,客户端向服务器请求网页 index.html。
协议规定,服务器只能响应 HTML 格式的字符串,不能响应别的格式。
<html>
<body>
Hello World
</body>
</html>
2
3
4
5
服务器发送完毕,就关闭 TCP 连接。
# HTTP/1.0
1996 年 5 月,HTTP/1.0 版本发布,内容大大增加。
首先,任何格式的内容都可以发送。这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。这为互联网的大发展奠定了基础。
其次,除了 GET 命令,还引入了 POST 命令和 HEAD 命令,丰富了浏览器与服务器的互动方式。
再次,HTTP 请求和响应的格式也变了。除了数据部分,每次通信都必须包括头信息(HTTP header),用来描述一些元数据。
其他的新增功能还包括状态码、多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等。
下面是一个 1.0 版的 HTTP 请求的例子。
GET / HTTP/1.0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5)
Accept: */*
2
3
第一行是请求命令,必须在尾部添加协议版本(HTTP/1.0)。后面就是多行头信息,描述客户端的情况。
# 响应格式
服务器的响应如下。
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
<html>
<body>Hello World</body>
</html>
2
3
4
5
6
7
8
9
10
响应的格式是头信息 + 空行 + 数据。其中,第一行是协议版本 + 状态码 + 状态描述。
# HTTP/1.0 缺点
HTTP/1.0 版的主要缺点是,每个 TCP 连接只能发送一个请求。发送数据完毕,连接就关闭,如果还要请求其他资源,就必须再新建一个连接。
TCP 连接的新建成本很高,因为需要客户端和服务器三次握手,并且开始时发送速率较慢(慢启动)。所以,HTTP/1.0 版本的性能比较差。随着网页加载的外部资源越来越多,这个问题就愈发突出了。
为了解决这个问题,有些浏览器在请求时,用了一个非标准的 Connection: keep-alive 字段。
这个字段要求服务器不要关闭 TCP 连接,以便其他请求复用。服务器同样响应这个字段Connection: keep-alive。
一个可以复用的 TCP 连接就建立了,直到客户端或服务器主动关闭连接。但是,这不是标准字段,不同实现的行为可能不一致,因此不是根本的解决办法。
# HTTP/1.1
1997 年 1 月,HTTP/1.1 版本发布,只比 1.0 版本晚了半年。它进一步完善了 HTTP 协议,一直用到了 20 年后的今天,直到现在还是最流行的版本。
# 持久连接
HTTP/1.1 版的最大变化,就是引入了持久连接(persistent connection),即 TCP 连接默认不关闭,可以被多个请求复用,不用声明 Connection: keep-alive。
客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。不过,规范的做法是,客户端在最后一个请求时,发送 Connection: close,明确要求服务器关闭 TCP 连接。
目前,对于同一个域名,大多数浏览器允许同时建立 6 个持久连接。
# 管道机制
HTTP/1.1 版还引入了管道机制(pipelining),即在同一个 TCP 连接里面,客户端可以同时发送多个请求。这样就进一步改进了 HTTP 协议的效率。
举例来说,客户端需要请求两个资源。以前的做法是,在同一个 TCP 连接里面,先发送 A 请求,然后等待服务器做出响应,收到后再发出 B 请求。管道机制则是允许浏览器同时发出 A 请求和 B 请求,但是服务器还是按照顺序,先响应 A 请求,完成后再响应 B 请求。
# Content-Length 字段
一个 TCP 连接现在可以传送多个响应,势必就要有一种机制,区分数据包是属于哪一个响应的。这就是 Content-length 字段的作用,声明本次响应的数据长度。
Content-Length: 3495
上面代码告诉浏览器,本次响应的长度是 3495 个字节,后面的字节就属于下一个响应了。
在 1.0 版中,Content-Length 字段不是必需的,因为浏览器发现服务器关闭了 TCP 连接,就表明收到的数据包已经全了。
# 分块传输编码
分块传输编码是指将数据分解成一系列数据块,并以一个或多个块发送,这样服务器可以发送数据而不需要预先知道发送内容的总大小。
使用 Content-Length 字段的前提条件是,服务器发送响应之前,必须知道响应的数据长度。
对于一些很耗时的动态操作来说,这意味着,服务器要等到所有操作完成,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据,就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer)。
因此,HTTP/1.1 版规定可以不使用 Content-Length 字段,而使用分块传输编码。只要请求或响应的头信息有 Transfer-Encoding 字段,就表明响应将由数量未定的数据块组成。
Transfer-Encoding: chunked
每个非空的数据块之前,会有一个 16 进制的数值,表示这个块的长度。最后是一个大小为 0 的块,就表示本次响应的数据发送完了。下面是一个例子。
HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
25
This is the data in the first chunk
1C
and this is the second one
3
con
8
sequence
0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 其他功能
HTTP/1.1 版还新增了许多请求方法:PUT、PATCH、HEAD、 OPTIONS、DELETE。
另外,客户端请求的头信息新增了 Host 字段,用来指定服务器的域名。
Host: www.example.com
有了 Host 字段,就可以将请求发往同一台服务器上的不同网站,为虚拟主机的兴起打下了基础。
# HTTP/1.1 缺点
虽然 1.1 版允许复用 TCP 连接,但是同一个 TCP 连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个响应,才会进行下一个响应。要是前面的响应特别慢,后面就会有许多请求排队等着。这称为"队头堵塞"(Head-of-line blocking)。
为了避免这个问题,只有两种方法:一是减少请求数,二是同时多开持久连接。这导致了很多的网页优化技巧,比如合并脚本和样式表、将图片嵌入 CSS 代码、域名分片(domain sharding)等等。如果 HTTP 协议设计得更好一些,这些额外的工作是可以避免的。
# HTTP/2
2015 年,HTTP/2 发布。它不叫 HTTP/2.0,是因为标准委员会不打算再发布子版本了,下一个新版本将是 HTTP/3。
# 二进制协议
HTTP/1.1 版的头信息只能是文本(ASCII 编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为帧(frame):头信息帧和数据帧。
二进制协议的一个好处是,可以定义额外的帧。HTTP/2 定义了近十种帧,为将来的高级应用打好了基础。如果使用文本实现这种功能,解析数据将会变得非常麻烦,二进制解析则方便得多。
HTTP2 二进制分帧图:

# 多路复用
HTTP/2 复用 TCP 连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或响应,而且不用按照顺序一一对应,这样就避免了"队头堵塞"。
举例来说,在一个 TCP 连接里面,服务器同时收到了 A 请求和 B 请求,于是先响应 A 请求,结果发现处理过程非常耗时,于是就发送 A 请求已经处理好的部分, 接着响应 B 请求,完成后,再发送 A 请求剩下的部分。
这样双向的、实时的通信,就叫做多路复用(Multiplexing)。
# 多路复用的发展史
- 图 1 请求方式,就是单次发送 request 请求,收到 response 后再进行下一次请求,显示是很低效的。
- 图 2 请求方式,使用了 HTTP/1.1 的管线化技术,一次性发送多个请求。
- 图 3 请求方式,暴露出 HTTP/1.1 的管线化技术的问题,响应请求的顺序必须和客户端发送请求的顺序一致。如果第一个请求阻塞后,后面的请求都需要等待,这就造成了队头阻塞。
- 图 4 请求方式,使用了 HTTP/2 的多路复用技术。将多个请求复用同一个 TCP 链接中,将一个 TCP 连接分为若干个流(Stream),每个流中可以传输若干消息(Message),每个消息由若干最小的二进制帧(Frame)组成。也就是将每个请求响应拆分为了细小的二进制帧(Frame),这样即使一个请求被阻塞了,也不会影响其他请求。
# 数据流
因为 HTTP/2 的数据包是不按顺序发送的,同一个连接里面连续的数据包,可能属于不同的响应。因此,必须要对数据包做标记,指出它属于哪个响应。
HTTP/2 将每个请求或响应的所有数据包,称为一个数据流(stream)。每个数据流都有一个独一无二的编号。数据包发送的时候,都必须标记数据流 id,用来区分它属于哪个数据流。另外还规定,客户端发出的数据流 id 一律为奇数,服务器发出的 id 为偶数。
数据流发送到一半的时候,客户端和服务器都可以发送信号(RST_STREAM 帧),取消这个数据流。HTTP/1.1 版取消数据流的唯一方法,就是关闭 TCP 连接。这就是说,HTTP/2 可以取消某一次请求,同时保证 TCP 连接还打开着,可以被其他请求使用。
客户端还可以指定数据流的优先级。优先级越高,服务器就会越早响应。
数据流、消息、帧
- 数据流:已建立的连接内的双向字节流,可以承载一条或多条消息。(一次 http 请求)
- 消息:与逻辑请求或响应消息对应的完整的一系列帧。(一个请求或响应)
- 帧:HTTP/2 通信的最小单位,每个帧都包含帧头,至少也会标识出当前帧所属的数据流。(http 标头,消息负载等)
这些概念的关系总结如下:
- 所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流。
- 每个数据流都有一个唯一的标识符和可选的优先级信息,用于承载双向消息。
- 每条消息都是一条逻辑 HTTP 消息(请求或响应),包含一个或多个帧。
- 帧是最小的通信单位,承载着特定类型的数据,例如 HTTP 标头、消息负载等。 来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
理解了这张图,数据流、消息、帧 就基本上懂了。

# 头信息压缩
HTTP 协议不带有状态,每次请求都必须附上所有信息。所以,请求的很多字段都是重复的,比如 Cookie 和 User Agent,一模一样的内容,每次请求都必须附带,这会浪费很多带宽,也影响速度。
HTTP/2 对这一点做了优化,引入了头信息压缩机制(header compression)。一方面,头信息使用 gzip 或 compress 压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。

# 服务器推送
HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。
常见场景是客户端请求一个网页,这个网页里面包含很多静态资源。正常情况下,客户端必须收到网页后,解析 HTML 源码,发现有静态资源,再发出静态资源请求。其实,服务器可以预期到客户端请求网页后,很可能会再请求静态资源,所以就主动把这些静态资源随着网页一起发给客户端了。
服务器端推送:

在 HTTP2 中,服务端可以在客户端某个请求后,主动推送其他资源。
可以想象以下情况,某些资源客户端是一定会请求的,这时就可以采取服务端 push 的技术,提前给客户端推送必要的资源,这样就可以相对减少一点延迟时间。当然在浏览器兼容的情况下你也可以使用 prefetch 。
# HTTP/2 缺点
虽然 HTTP/2 解决了很多之前旧版本的问题,但是它还是存在一个巨大的问题:因为 HTTP/2 使用了多路复用,一般来说同一域名下只需要使用一个 TCP 连接。当这个连接中出现了丢包的情况,整个 TCP 都要开始等待重传,也就导致了所有数据都被阻塞了。
虽然这个问题并不是它本身造成的,而是底层支撑的 TCP 协议的问题。那么可能就会有人考虑到去修改 TCP 协议,其实这已经是一件不可能完成的任务了。因为 TCP 存在的时间实在太长,已经充斥在各种设备中,并且这个协议是由操作系统实现的,更新起来不大现实。
# HTTP/3
HTTP/3 于 2018 年 10 月底提出,在 11 月于曼谷举行的 IETF 103 大会期间进行了讨论并达成初步的共识。
基于 HTTP/2 底层 TCP 的一些缺陷,Google 更起炉灶搞了一个基于 UDP 协议的 QUIC 协议,并且使用在了 HTTP/3 上,当然 HTTP/3 之前名为 HTTP-over-QUIC,从这个名字中我们也可以发现,HTTP/3 最大的改造就是使用了 QUIC,接下来我们就来学习关于这个协议的内容。
QUIC 基于 UDP 协议,但是在原本的基础上新增了很多功能,比如多路复用、0-RTT、使用 TLS1.3 加密、流量控制、有序交付、重传等等功能。我们挑选几个重要的功能学习看一下。
# QUIC-多路复用
虽然 HTTP/2 支持了多路复用,但是 TCP 协议终究是没有这个功能的。QUIC 原生就实现了这个功能,并且传输的单个数据流可以保证有序交付且不会影响其他的数据流,这样的技术就解决了之前 TCP 存在的问题。
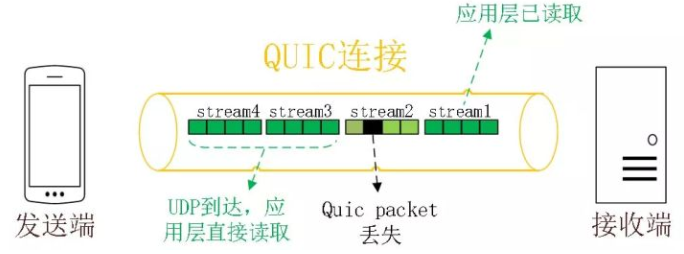
同 HTTP2.0 一样,同一条 QUIC 连接上可以创建多个 stream,来发送多个 HTTP 请求,但是,QUIC 是基于 UDP 的,一个连接上的多个 stream 之间没有依赖。比如下图中 stream2 丢了一个 UDP 包,不会影响后面跟着 Stream3 和 Stream4,不存在 TCP 队头阻塞。虽然 stream2 的那个包需要重新传,但是 stream3、stream4 的包无需等待,就可以发给用户。
并且 QUIC 在移动端的表现也会比 TCP 好。因为 TCP 是基于 IP 和端口去识别连接的,这种方式在多变的移动端网络环境下是很脆弱的。但是 QUIC 是通过 ID 的方式去识别一个连接,不管你网络环境如何变化,只要 ID 不变,就能迅速重连上。
# 0-RTT
通过使用类似 TCP 快速打开的技术,缓存当前会话的上下文,在下次恢复会话的时候,只需要将之前的缓存传递给服务端验证通过就可以进行传输了。
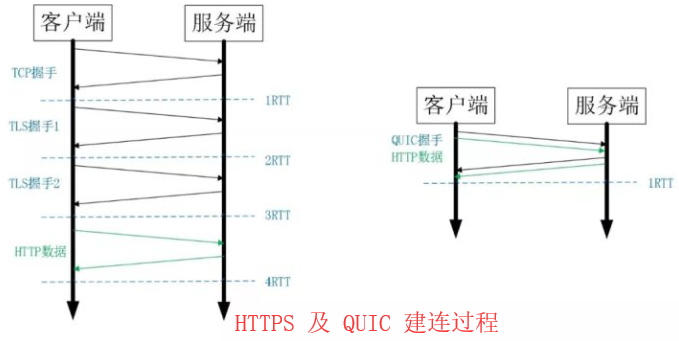
上图左边是 HTTPS 的一次完全握手的建连过程,需要 3 个 RTT。就算是会话复用也需要至少 2 个 RTT。
而 QUIC 呢?由于建立在 UDP 的基础上,同时又实现了 0RTT 的安全握手,所以在大部分情况下,只需要 0 个 RTT 就能实现数据发送,在实现前向加密的基础上,并且 0RTT 的成功率相比 TLS 的会话记录单要高很多。
# 加密认证的报文
TCP 协议头部没有经过任何加密和认证,所以在传输过程中很容易被中间网络设备篡改,注入和窃听。比如修改序列号、滑动窗口。这些行为有可能是出于性能优化,也有可能是主动攻击。
但是 QUIC 的 packet 可以说是武装到了牙齿。除了个别报文比如 PUBLIC_RESET 和 CHLO,所有报文头部都是经过认证的,报文 Body 都是经过加密的。
这样只要对 QUIC 报文任何修改,接收端都能够及时发现,有效地降低了安全风险。
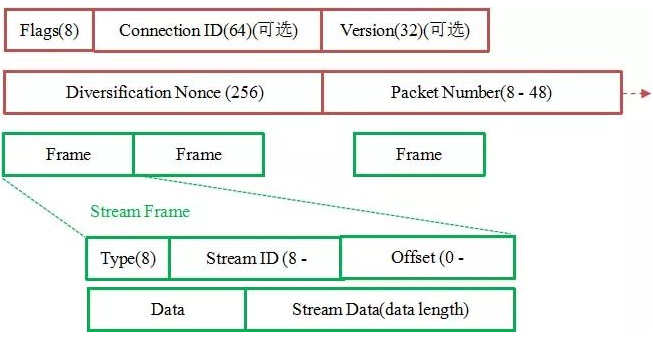
如上图所示,红色部分是 Stream Frame 的报文头部,有认证。绿色部分是报文内容,全部经过加密。
# 向前纠错机制
QUIC 协议有一个非常独特的特性,称为向前纠错 (Forward Error Correction,FEC),每个数据包除了它本身的内容之外,还包括了部分其他数据包的数据,因此少量的丢包可以通过其他包的冗余数据直接组装而无需重传。向前纠错牺牲了每个数据包可以发送数据的上限,但是减少了因为丢包导致的数据重传,因为数据重传将会消耗更多的时间(包括确认数据包丢失、请求重传、等待新数据包等步骤的时间消耗)。
案例
假如说这次我要发送三个包,那么协议会算出这三个包的异或值并单独发出一个校验包,也就是总共发出了四个包。
当出现其中的非校验包丢包的情况时,可以通过另外三个包计算出丢失的数据包的内容。
当然这种技术只能使用在丢失一个包的情况下,如果出现丢失多个包就不能使用纠错机制了,只能使用重传的方式了。
# HTTP 请求与相应
HTTP 请求是由请求行、消息报头、请求正文组成。其中请求行包含请求方法、请求 URI 和 HTTP 协议的版本号。
HTTP 响应是由状态行、消息报头、响应正文组成。其中状态行包含 HTTP 协议的版本号、响应状态码和状态码的文本描述。
# HTTP 请求方法
常见的 HTTP 请求方法如下:
- GET: 请求获取 Request-URI 所标识的资源(4K 大小)。
- POST: 在 Request-URI 所标识的资源后附加新的数据(修改数据)。
- HEAD: 请求获取由 Request-URI 所标识的资源的响应消息报头(简易版的 get,只返回请求头)。
- PUT: 请求服务器存储一个资源,并用 Request-URI 作为其标识(增加数据)。
- DELETE:请求服务器删除 Request-URI 所标识的资源。
- TRACE: 请求服务器回送收到的请求信息,主要用于测试或诊断 。
- CONNECT:保留将来使用 。
- OPTIONS:请求查询服务器的性能,或者查询与资源相关的选项和需求。
# HTTP 常用的请求报头
常见的 HTTP 请求报头如下:
- Accept 请求报头域用于指定客户端接受哪些类型的信息。eg:Accept:image/gif,Accept:text/ html。
- Accept-Charset 请求报头域用于指定客户端接受的字符集。
- Accept-Encoding:Accept-Encoding 请求 报头域类似于 Accept,但是它是用于指定可接受的内容编码。
- Accept-Language 请求报头域类似于 Accept,但是它是用于指定一种自然语言。
- Authorization 请求报头域主要用于证明客户端有权查看某个资源。当浏览器访问一个页面时,如果收 到服务器的响应代码为 401(未授权),可以发送一个包含 Authorization 请求报头域的请求,要求服务 器对其进行验证。
- Host 请求报头域主要用于指定被请求资源的 Internet 主机和端又号,它通常从 HTTP URL 中提取出来 的,发送请求时,该报头域是必需的。
- User-Agent 请求报头域允许客户端将它的操作系统、浏览器和其它属性告诉服务器。
# HTTP 常用的响应报头
常见的 HTTP 响应报头如下:
- Location 响应报头域用于重定向接受者到一个新的位置。Location 响应报头域常用在更换域名的时候。
- Server 响应报头域包含了服务器用来处理请求的软件信息。与 User- Agent 请求报头域是相对应的。
- WWW-Authenticate 响应报头域必须被包含在 401(未授权的)响应消息中,客户端收到 401 响应消息时候,并发送 Authorization 报头域请求服务器对其进行验证时,服务端响应报头就包含该报头域。
# HTTP 常用的实体报头
每一个请求和响应消息都可以传送一个实体。一个实体由实体报头和实体正文组成,但并不是说实体报头和实体正文要在一起发送,可以只发送实体报头。在实体报头中定义了关于实体正文和请求所标识的资源的元信息。
- Content-Encoding 实体报头被用作媒体类型的修饰符,它的值指示了已经被应用到实体正文的附加内容的编码,因而要获得 Content-Type 报头域中所引用的媒体类型,必须采用相应的解 码机制。
- Content-Language 实体报头描述了资源所用的自然语言。
- Content-Length 实体报头用于指明实体正文的长度,以字节方式存储的十进制数字来表示。
- Content-Type 实体报头用语指明发送给接收者的实体正文的媒体类型。 Last-Modified 实体报头用于指示资源的最后修改日期和时间。 Expires 实体报头给出响应过期的日期和时间。
# HTTP 缓存策略
# Cookie 和 Session
- Cookie 是保存在客户端的小段文本,每当客户端发起一个请求发送会将该请求 URL 下的所有 Cookie 发送到服务器端。
- Session 则保存服务器段,通过唯一的值 SessionID 来区别每一个 用户。SessionID 随每个连接请求发送到服务器,服务器根据 SessionID 来识别客户端,再通过 Session 的 Key 获取 Session 值。
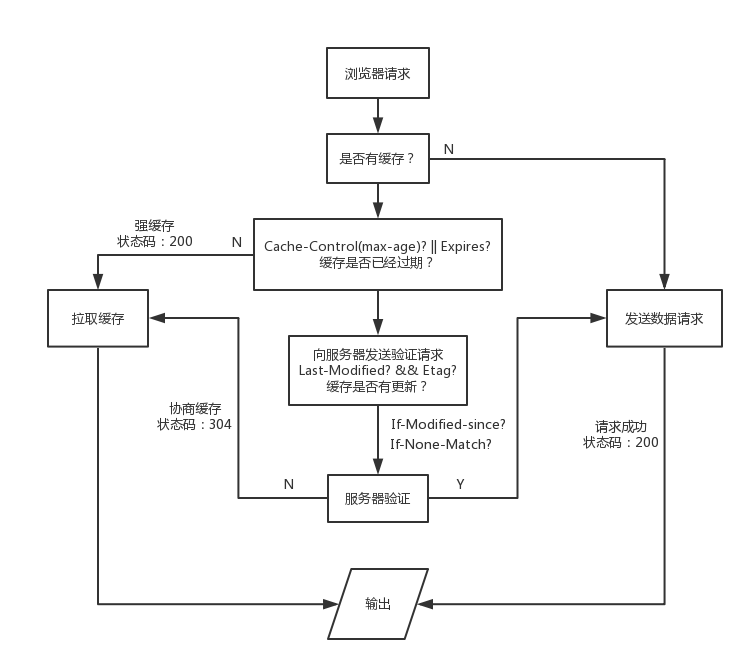
# Etag/If-None-Match 策略
- Etag:web 服务器响应请求时,告诉浏览器当前资源在服务器的唯一标识(生成规则由服务器决定)。
- If-None-Match:当资源过期时(使用 Cache-Control 标识的 max-age),发现资源具有 Etage 声明,则再次向 web 服务器请求时带上头 If-None-Match(Etag 的值)。Web 服务器收到请求后发现 有头 If-None-Match 则与被请求资源的相应校验串进行比对,决定返回 200 或 304。
# Last-Modified/If-Modified-Since 策略
- Last-Modified:标示这个响应资源的最后修改时间。Web 服务器在响应请求时,告诉浏览器资源的最后修改时间。
- If-Modified-Since:当资源过期时(使用 Cache-Control 标识的 max-age),发现资源具有 Last-Modified 声明,则再次向 web 服务器请求时带上头 If-Modified-Since,表示请求时间。web 服务器收到请求后发现有头 If-Modified- Since 则与被请求资源的最后修改时间进行比对。若最后修改时间较新,说明资源又被改动过,则响应整片资源内容(写在响应消息包体内),HTTP 200;若最后修改时间较旧,说明资源无新修改,则响应 HTTP 304(无需包体,节省流量),告知浏览器继续使用所保存的 cache。
http 缓存策略图:
# 相关链接
← 设备像素比 HTTPS 协议总结 →